Fine-tuning a safeguarding classifier for UK secondary schools
A short engineering note on how we adapted a general-purpose language model to UK safeguarding standards - what we did, what it changed, and what we'd do differently next time.
Tom Waszkowycz, CTO · ~6 min read
Every student message on the Inkling platform is screened for safeguarding concerns before, during, and after a tutoring session. The signal feeds the dashboard our Designated Safeguarding Leads (DSLs) review each week, and in the most serious cases triggers immediate escalation.
Getting this right is non-negotiable. Under-flag and you miss a child who needs support; over-flag and you bury the genuine signal in noise, and the DSL stops trusting the tool. The categories and severity bands that matter - bullying, self-harm, neglect, exploitation, radicalisation, and the rest of the KCSIE framework - are specific to UK schools, and the threshold for action sits in a place that a general-purpose model has no reason to know about.
Our first version of this classifier was a prompt-engineered call to off the shelf Gemini 2.5 flash. It worked, but it occasionally over-flagged, and got severity wrong about a quarter of the time. So we built our first fine-tuned model. This note is what we found.
The result, in one number
Baseline (base model): 61 / 69 — 88.4% effective pass rate Fine-tuned v1: 64 / 69 — 92.8% effective pass rate (+4.4 percentage points)
The "effective pass rate" combines exact matches with cases where the model identified the correct concern type but placed it at an adjacent severity (e.g. medium where we expected high). For a screening classifier whose output triggers human review, an adjacent-severity match still triggers the right escalation path, so we count it as effective.
The strict exact-match rate also improved: from 35/69 (50.7%) to 39/69 (56.5%). Hard failures - wrong concern type, missed disclosure, or false positive - dropped from 8 to 5.
What we did
Base model | Gemini 2.5 Flash, via Google Cloud's Vertex AI managed tuning service |
Training method | Supervised fine-tuning (SFT) · ~15 epochs · LoRA adaptor |
Training data | 254 synthetic transcript-and-label examples covering 21 KCSIE-aligned concern categories, including 75 deliberately ambiguous false-positive cases. Each example is a short tutor-student transcript and the expected JSON output (concern type, severity, recommended action). |
Data generation | Two-stage LLM pipeline: a generation pass produced candidate transcripts and labels; an independent review pass re-labelled each example as a safeguarding lead would, with disagreements adjudicated and unrealistic examples dropped. |
Split | 90% training, 10% validation, stratified by category. A separate test set of 69 hand-curated cases - never seen during training - was used for all evaluation reported here. |
Eval | Each test transcript is passed to the model; the returned JSON is compared to expected concerns, scoring exact category-and-severity matches, adjacent-severity matches, and failures. Run on the same harness against baseline and tuned models. |
The point wasn't to teach the model what bullying is. It already knows. The point was to calibrate it to a specific severity standard, a specific output schema, and a specific notion of when something warrants a DSL's attention today.
Where the gains came from
The most useful view of the result is per-category. The fine-tuned model improved on four categories the baseline handled poorly, held its ground on the categories that were already solid, and regressed on one.
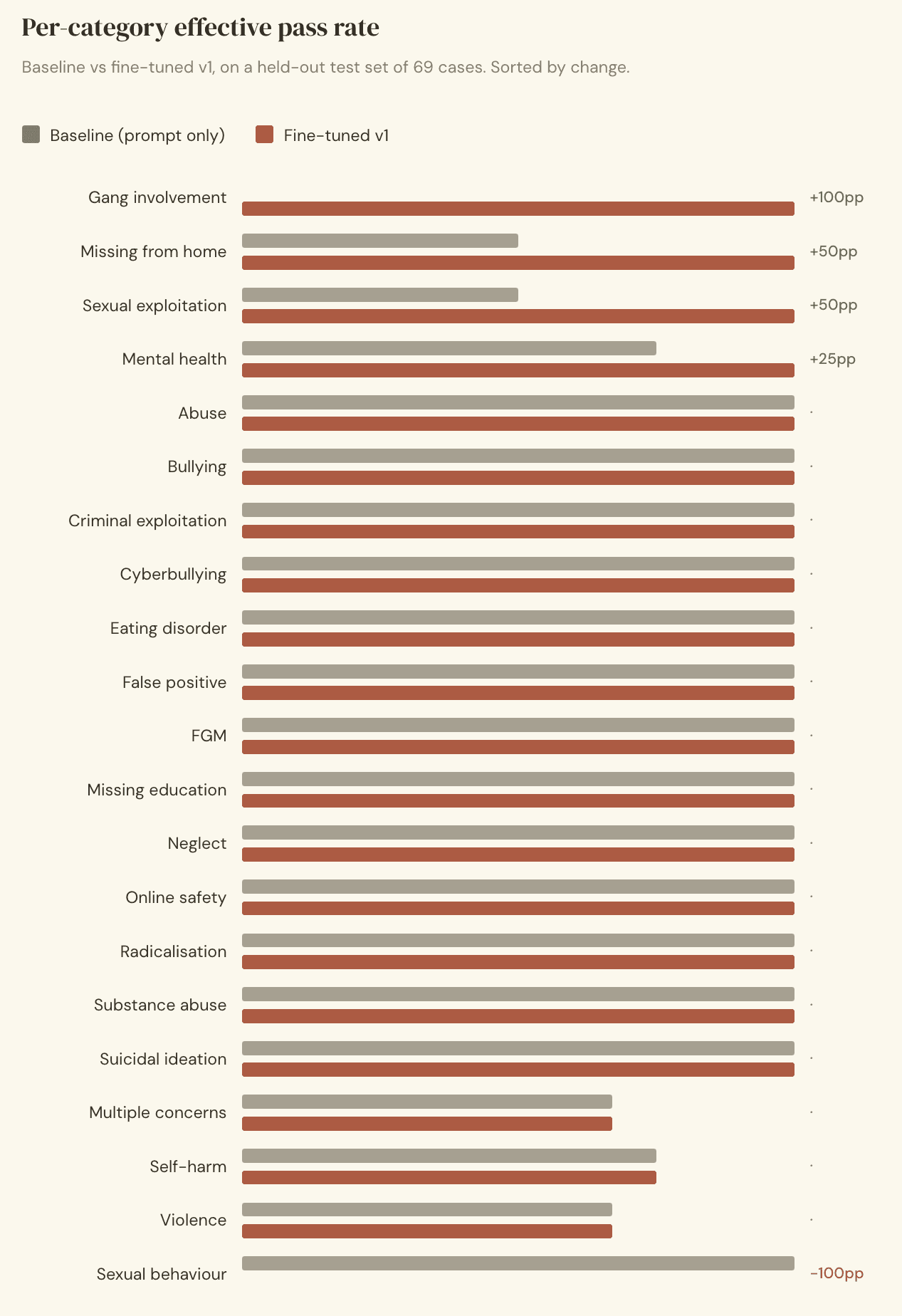
Test set: 69 cases, 21 categories. Sample size per category ranges from 2 to 10, which limits per-category statistical confidence; rare categories are particularly sensitive to single-case flips. Aggregate numbers (61/69 → 64/69) are the most robust signal.
Three categories worth noting:
Gang involvement (0/2 → 2/2). The baseline missed both cases entirely. The fine-tuned model identified both correctly. This is the category fine-tuning is best suited to: rare-but-serious cases where a general model has limited reliable signal and needs calibration to the specific patterns that matter.
Sexual exploitation (1/2 → 2/2) and missing from home (1/2 → 2/2). Similar story. Both improved cleanly without any false-positive cost.
Sexual behaviour (2/2 → 0/2). The one regression. Both cases now classify as a related but different category. With only two test examples this is partly a small-sample artefact, but it's also a real signal that our training data didn't draw a clear enough line between sexual behaviour and sexual exploitation. This is the most concrete fix on the v2 backlog.
What's next
Three things on the v2 list, in roughly that order:
Disambiguate the category boundaries that surfaced as weak in this round, particularly sexual behaviour vs sexual exploitation. This means specific training examples that draw the line and a category-boundary rubric our reviewers apply consistently.
Expand the test set. Sixty-nine cases were enough to demonstrate v1 improvements; they aren't enough to detect smaller regressions. We're aiming for ~250 hand-curated test cases, with at least ten per category.
We'll publish another note when v2 is shipped.
__________
Model card
Following the model card conventions established by Mitchell et al. (2019).
Model details
Name |
|
Version | v1.0 · May 2026 |
Base model | Gemini 2.5 Flash |
Training method | Supervised fine-tuning via Vertex AI managed tuning (LoRA adaptors) |
Owners | Inkling (GGTW Education Limited) |
Contact |
Intended use
The model screens transcripts of conversations between AI tutors and UK secondary school students (ages 13–16) for safeguarding concerns. For each transcript it outputs a structured list of identified concerns, each with a concern type, severity (low / medium / high), recommended action, and supporting evidence drawn from the transcript.
Output feeds the Inkling safeguarding dashboard reviewed by a school's Designated Safeguarding Lead. The model is one component in a multi-layered safeguarding workflow and is not intended for autonomous decision-making.
Out-of-scope uses
Autonomous safeguarding decisions without human DSL review
Use outside UK secondary school contexts
Use with adult populations or in non-educational settings
Real-time crisis intervention (the model is screening, not triage)
Diagnostic or clinical use of any kind
Training data
254 synthetic transcript-and-label examples covering 21 KCSIE-aligned categories: bullying, cyberbullying, abuse, neglect, self-harm, suicidal ideation, mental health, eating disorders, substance abuse, violence, gang involvement, radicalisation, criminal exploitation, sexual exploitation, sexual behaviour, FGM, online safety, missing from education, missing from home, multiple-concern cases, and deliberately ambiguous false-positive cases.
Each example consists of a short tutor-student transcript (6–14 turns) and an expected JSON output. Examples were generated by an LLM under a detailed style and category brief, then independently reviewed by a second LLM applying a stricter rubric; unrealistic or mislabelled examples were dropped or relabelled. No real student data was used in training v1.
Evaluation
Evaluation was performed on a held-out test set of 69 hand-curated cases distributed across the same 21 categories, including 10 false-positive cases designed to test for over-flagging. The test set was constructed before training and never exposed to the model during fine-tuning.
The primary metric is per-test classification correctness, scored as PASS (exact concern type and severity match), PARTIAL (correct concern type, adjacent severity), or FAIL.
Metrics
Exact pass rate | 39/69 (56.5%) — baseline 35/69 (50.7%) |
Effective pass rate | 64/69 (92.8%) — baseline 61/69 (88.4%) |
Hard failures | 5/69 (7.2%) — baseline 8/69 (11.6%) |
False positive cases | 10/10 correctly classified as non-concerns (baseline: 10/10) |
Limitations
Sample size. 69 test cases is small. Categories with two examples (e.g. FGM, gang involvement) cannot reliably distinguish improvements from noise individually; aggregate metrics are the most robust signal.
Synthetic training data. The training set was LLM-generated under structured constraints. While reviewed for realism, it may underrepresent the linguistic and emotional variation found in real student disclosures.
Category boundary regression. The v1 model regressed on the sexual behaviour category, classifying both test cases as sexual exploitation. Category disambiguation is a known weakness scheduled for v2.
Severity calibration. Around 36% of cases land in the PARTIAL bucket - correct concern, adjacent severity. For a screening classifier this is acceptable; for downstream features that branch on severity exactly, additional calibration is needed.
UK-only scope. Training data, severity standards, and category taxonomy are aligned to UK KCSIE. The model should not be deployed in other jurisdictions without re-training.
No real-world deployment metrics yet. All numbers reported are from offline evaluation. Production deployment data will be incorporated into future versions.
Ethical considerations
The model operates in a high-stakes domain. Design decisions are oriented toward minimising harm in both directions: missing a genuine concern, and over-flagging a routine utterance. The architecture treats every model output as a signal for human review rather than an autonomous decision.
Data residency: model training was performed in the United States; production inference is deployed in the European Union. Training used synthetic data only. The deployment is covered under Inkling's data protection impact assessment available on request.
Bias considerations: synthetic training data was generated to include varied student personas, names, and contexts. We have not yet conducted a systematic bias audit; this is on the v2 backlog.